
Hey there...
My name is Pawel Grabowski. I am a startup SEO consultant specializing in helping early-stage startups develop and deploy successful SEO programs.
Learn more about me or hire me to run SEO for your startup.

by Startup SEO Consultant,
Pawel Grabowski
This is the only guide to technical SEO dedicated solely to startups.
And no, of course, I am not trying to stir up anything by that claim.
But it's really irritating that most technical SEO guides for startups are de facto just guides to technical SEO in general.
Not only such content focuses only on offering a generic overview of this SEO strategy, it also usually fails to take the typical startup situation into consideration.
As a result, it offers no meaningful and practical information that would be helpful to a founder like you.
It makes sense, of course. It's far easier to talk about technical SEO in generic terms. Any SEO could do it.
But presenting it from a highly-specific situation - like optimizing a startup website - requires extensive expertise and experience.
Unfortunately, the result is that, upon reading such generic guides, founders jump into focusing on aspects of their sites that have absolutely no relevance to their current situation, and would not (and I do mean it!) have any positive impact on their organic presence.
Or to put it bluntly, they end up wasting time.
This guide is different.
It contains only the information you need to optimize a startup site for technical SEO, and ignores all the stuff that does not apply to a startup (but other technical SEO guides cover so extensively).
I mean it.
Here's what you'll learn, exactly:
In other words, this guide to technical SEO focuses on you - a startup founder who wants to a.) ensure that they've ticked all the boxes when it comes to technical SEO and b.) doesn't want to waste time working on stuff that's just not relevant to their startup at present.
And how do I know that this guide is different? Well, for one, all the information here is comes from my 15 years of working as a startup SEO consultant, optimizing startup websites for SEO, and building organic growth engines for early-stage startups.

This chapter is all about helping you understand the general concept of technical SEO.
Even though, we're only looking at technical SEO from the startup perspective, I think it's important that you at least have a broad understanding of the strategy.
So, in this chapter, you'll learn what technical SEO is, how it helps boost your site's rankings, and also, how much effort your startup should put into technical SEO for your startup.
When we, SEOs, use the term - technical SEO - we, typically, refer to various (and numerous) strategies that ensure that a website is developed in a way to make it easy for search engines to find, crawl, analyze, index, and rank its content.
Now, I admit; such a definition doesn't really tell you much about what technical SEO is.
This is, partially, because technical SEO covers so many aspects of search engine optimization that it's hard to describe it in relation to a single aspect.
So, let's break it down a little.
And so...
It's mostly about technical.
As the first word of its name suggests, technical SEO concerns itself mostly with technical elements of the website - It's architecture, performance, and various others. (BTW, don't worry if any of this still sounds a little confusing. We will be covering all those elements in great detail later in this guide.)
But note that I said mostly. This is because there are some content-related elements that would also overlap with technical SEO. Things like duplicate content, for example, would affect both your content optimization and technical SEO. (Again, we will cover those in-depth shortly.)
On the whole, however, technical SEO is about ensuring that search engines can get to your content quickly and without much effort so they can analyze it, understand what it is about, and rank it for relevant search queries.
Your pages cannot rank unless Google and other search engines learn about them first, crawl and read those pages, analyze and understand the content, and add them to their index.
For example, here are pages that have been blocked from search engine crawlers.

This page will not rank. No one will ever see it in the search results. And so, the page will never contribute to or help build your startup's organic growth.
For the opposite to happen, it would first need to become accessible to crawlers.
Side note: Page in my example above have been blocked from crawlers deliberately. In this case, I chose not to have them crawled and included in Google's index. However, sometimes pages are simply inaccessible as a result of an issue or an error, and that's one of the issues that technical SEO helps eliminate.
Technical SEO covers a wide range of strategies and activities to optimize your site for:
In other words, technical SEO is your secret weapon to create and maintain a website that Google would have no problems with crawling and indexing.
That is a good question, and there are several reasons for that.
For one, your startup site is, most likely, quite small.
You probably have a handful of pages only, and perhaps some blog content. However, all in all, your site is nothing compared to large enterprises with their hundreds of thousands of pages, and so on.
Take Hubspot, for example. Google reports to have 558 thousand of its pages in the index.

For Salesforce, it's nearly 2 million pages!

Compare that with a typical startup site, one that hasn't had any major SEO work done to it.

Analyzing it quickly shows me that it has only 79 indexed pages.
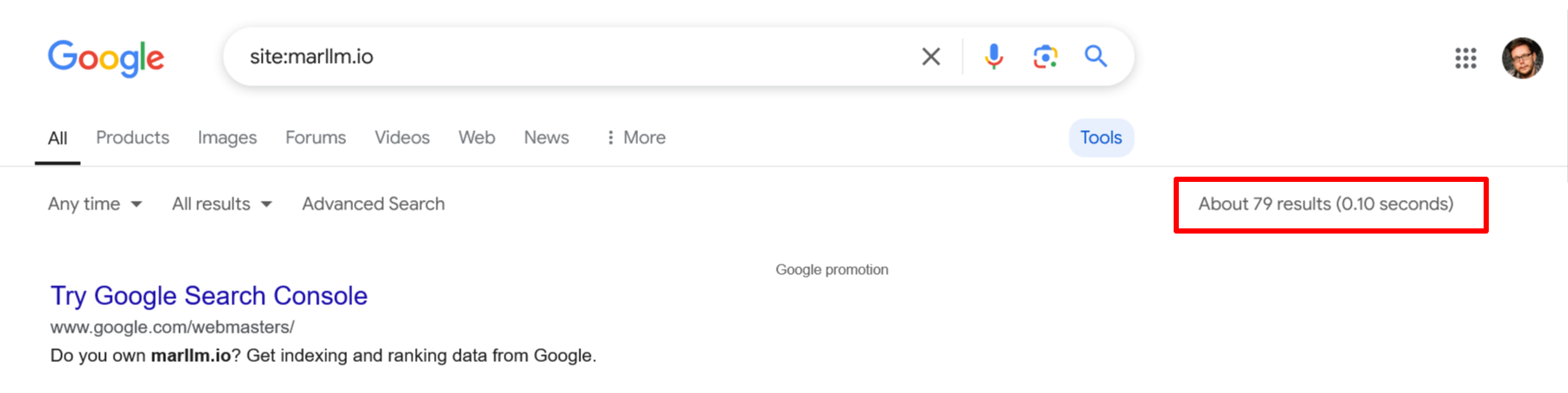
I suppose it's hard to image that such a small site would experience many technical SEO issues.
And it doesn't.
At least not to the same extent as those large, enterprise website with hundreds of thousands of pages.
What this means to you is that you don't need to focus on as many aspects of technical SEO as a large site.
At the same time, you do need to ensure that you've built a strong technical foundation for SEO. Otherwise, no matter what a fantastic and useful content you publish, it will still perform poorly (if at all.)

In this chapter, you'll learn all the strategies and elements that technical SEOs usually work on when optimizing a site.
We'll go through each of these elements in turn, discussing it's role in technical SEO, why it's important, and how it works.
The term - site taxonomy - sounds very technical (and perhaps even academic.) But the concept behind it is actually pretty simple.
Site taxonomy is nothing else than the hierarchical structure of your website. You could also refer to it as "navigation," although I'd recommend that you separate the two terms. It's easy to confuse taxonomy for the main navigation at the top of your site, whereas in fact, it is more than this.
But nonetheless, taxonomy defines how your content is organized (i.e., by page type, category, etc.) and how this works in practice (i.e., navigation and internal linking between pages.)
Here's an example taxonomy showing relationships between various pages on a site.
Why is site taxonomy important to technical SEO?
Well, for one, site taxonomy helps with improving crawling and indexing the site.
As you remember from the previous chapter, for your pages to rank, search engines must first find and access them, crawl the content, and finally, understand it to index them for relevant keywords.
With a clear site taxonomy, Google and other search engines will be able to quickly access all the content on your site, and that's regardless of whether that content is linked from the main navigation or not.
They will also be able to better understand relationships between pages, and get a clear idea of what category does your site belong to, what topics you cover, how well you cover them, etc.
Elements of site taxonomy for technical SEO.
When we optimize the taxonomy, we usually focus on four core elements:
ADDITIONAL READING:The Best Two Taxonomy Methods to Boost SEO
I've used both terms - crawling and indexing - several times in this guide, and now is the time we look at both more closely.
Crawling is the process that search engines use to discover and understand new content (or revisit already indexed pages to see if they haven't been updated.)
It's only if a page can be crawled, it can also be included in a search engine index and appear in the search results.
To crawl the web, search engines use software we refer to as web crawlers (or search engine bots.)
Crawlers follow links on pages, doing pretty much the same thing you do when you land on a page, and use the navigation, as well as both internal and external links to find and access other content.
Similarly, crawlers go from link to link and collect information about each page they encounter. This information, in turn, helps the search engine index those pages correctly and rank for relevant search queries.
Why is crawling so important to technical SEO?
Well, as I mentioned (many) times already, unless your page can be crawled, it will not rank.
And so, when optimizing the site for technical SEO, your job is to make sure that crawlers can access every page on the site (or at least, every page that you want them to access - more on this shortly.)
It's that simple.
Unfortunately, we often place roadblocks on the crawlers' paths, preventing them from accessing our content.
Broken links, too many redirects, or even burying pages too deep in the taxonomy might stop crawler in its tracks. Similarly, you or your dev team might have accidentally blocked a page or whole section of the site from crawling.
Finally, on occasion Google might deep pages as thin (meaning, it does not see any reason why it should crawl them.)
That's why, crawlability (and taxonomy) is usually the first thing we check for when auditing the site for any technical issues.
How to monitor your startup site's crawling?
You do that in Google Search Console, under Indexing -> Pages.
Here are some methods to uncover those:

The report lists the current status of your website indexing, including all the reasons why pages might not have been indexed. One of the potential reasons is "Discovered, currently not crawled." That's where you'll find a list of pages that Google might have deemed not worthy of crawling.

ADDITIONAL READING:What is Crawlability in SEO and How to Improve It
How to improve crawling?
There are several strategies you can use to boost crawlability of your site:
While crawling is all about search engines discovering and understanding new content, indexing helps them process that information to rank it for relevant search queries.
And just like with crawling, there are ways by which you can affect that process.
For example, you can tell the search engine not to index a particular piece of content. In this case, even though the crawler is able to access the page, following your directive, it will not include it in the index.
This is done by placing a noindex directive within the page's head element, like this: <meta name="robots" content="noindex"/>
You can also include a disallow directive in the Robots.txt file, which will prevent Google and other bots from accessing and indexing the content.
Finally, you can use a Canonical Tag to tell the search engine to index a different page instead of the one it has just crawled. This method is useful if you have duplicate content on the site. In this case, users will see those different (yet almost identical) pages, but the search engine will index only one of them.
Why monitoring indexing is important for SEO?
Generally, and providing that you fixed any crawlability issues, Google should be able to index your pages without problems.
However, at times, we can unintentionally hinder that process.
One incredibly common situation is launching a new section of a website (or even the entire new website.)
Usually (and rightly so), developers add the noindex tag to the new version as they build it.
It makes sense. You don't want search engines to crawl and index it while it is being built on a staging server.
But unfortunately, they often forget to remove it after publishing the new section, resulting in that whole bunch of pages getting deindexed.
I am sure that you've experience this issue more than once. And because of that, you probably even intuitively understand its importance.
After all, nobody wants to wait for the content to load. We want to see the information we've been searching for right away.
Unfortunately, it is quite easy to negatively affect the time it takes for a page to load.
For example, you could be using too big images that take longer to load. Or have other heavy resources on the page.
Similarly, server issues might affect how long a person needs to wait for the content to load.
That's why technical SEOs put a lot of emphasis on ensuring that pages are as light as possible, and will load fast even on connections that are slower than usual.
Why is page speed important for technical SEO?
Well, search engines approach the issue similarly. They understand how frustrating waiting for a page to load can be, and as a result, tend to put more emphasis on content that loads fast.
And so, fast-loading page provides a much better user experience. It delivers the information the person wants quicker, and in doing that, it aligns with what the search engine wants to deliver.
The above three elements form the core of technical SEO. These elements are what you, a startup founder, must focus on if you want your site to rank and start driving traffic and signups.
But there are several other factors that might not play as crucial role to your SEO now. Granted, as your site grows, there might come a need to work on them. For now, however, your efforts are better spent working on the above three.
Nonetheless, here are other aspects of the site's setup that technical SEOs often evaluate in their work:

In this highly practical section, I will show you exactly how to optimize your startup site for technical SEO - step by step.
We'll cover all the steps you need to take to ensure that you've built a strong technical SEO foundation on your site. You'll learn exactly what you need to paying attention to when adding more content to your site.
First things first... You actually can't do SEO successfully without data.
And although some of this data comes from 3rd parties (like your rank tracker or keyword research tool,) the majority of the most important information - your website's actual performance in the search results - comes directly from Google through the Google Search Console (GSC, for short.)
Google Search Console is a free tool by the search engine that helps website owners monitor, maintain, and optimize their site's presence in Google search results.
I do realize that this definition is a mouthful but it really describes what GSC is pretty well.
You see, GSC is the best source of insights into your website performance, indexing issues, search traffic, and even keyword rankings (although, you should keep in mind that these are averages, not exact rankings.)
In short, GSC delivers a ridiculous (in a good way) amount of a lot of data.
For example, here's the main Performance report showing traffic, visibility, and rankings over time.

And here is an indexing report showing different reasons why various pages didn't get indexed (we talked about this earlier in this guide, remember?)

The thing is, to access all this data, you first need to add your site to GSC so that the system can start collecting information about your site's performance.
Here's how to do it.
1/ Click on the "Search Property" button in the upper left corner. It's located right under the GSC logo.
Then, click "Add property."

2/ Select "Domain" to add your entire site.
Just type in your domain into the relevant box and hit Continue.

3/ Verify domain ownership.
Before GSC can start collecting your site's data, the system needs to verify whether you indeed are the owner of the site.
(And you have to agree that it makes sense. You wouldn't like your competitors to start going through your performance data, after all... )
GSC offers several ways to verify your site. You can choose any of them, and once you've applied it, GSC will start collecting your data.

I'm sure you've heard the term - sitemap -before. It's a simple file (or a set of files - more on that in just a moment) that lists all pages on a domain, including several additional data points like when the page was created or updated, etc.
Here's a fragment of this site's sitemap.

This seemingly simple and inconspicuous file plays an enormous role in your SEO.
For one, it's one of the core places where search engines learn about new pages to crawl and index.
Just take a look here. This GSC report shows crawl data about a specific page, include how the search engine learnt about the page in the first place. And lo and behold, as it happens, it first discovered it in a sitemap.

Naturally, it's not like Google (or other search engines) wouldn't learn about the page without a sitemap.
But having one certainly helps.
The best way is to have the sitemap created dynamically by your CMS. Now, naturally, that assumes your site runs on a CMS system (Wordpress, Webflow, Framer, etc.)
All these platforms have the ability to create the sitemap and update it every time you publish or update a piece of content. All you have to do is to submit the sitemap to GSC, and the system will do the rest.
But, from experience, I know that many founders, particularly technical ones, prefer to build static sites.
In this case, the situation is a little bit more challenging. And that's because you'll have to update the sitemap every time you add or change content on your site.
So, every time you create a new page, or another piece of content, you'll have to add it manually to the sitemap.xml file, and upload that file to the server.
Not ideal but if you insist on having a static site, there is no other way.
You can use crawlers like Screaming Frog or Sitebulb (my favorite website crawler, by the way,) to create the sitemap for you, and then build it up on that.
To create a sitemap with Sitebulb:

Once you've created the sitemap, upload it to the root of your server and submit it to GSC so that the search engine can crawl it and learn about all URLs on your site.
1. Click on Sitemaps in the left side menu (under the Indexing section)

2. Type in your sitemap URL (which, because you need to upload it to the root folder, would be something like: yourdomain.com/sitemap.xml)

Done! The search engine will crawl (and then, revisit) this file regularly to learn about changes to your site.
Robots.txt is an interesting file.
As you can tell by the file extension, it's just a simple text file. For many websites, it's even completely blank or contains just a handful of lines of text (or less.)
And yet, it's a superbly important element of your technical site setup.
The Robots.txt file basically tells search engines which URLs (individual pages or entire sections of the site) it can access and crawl on your site.
In other words, it tells Google (and other search engines) what sections you don't want it to crawl.
It's that simple.
For example, you might have a whole bunch of landing pages created solely for a PPC campaign.
These pages help you keep the relevancy score (and the CPC down.) But they contain mostly duplicate content. So, from the SEO point of view, they might cause your site some harm.
You can use Robots.txt file to notify the search engine that you don't want it to crawl and index those pages.
Another example. Say, your product creates public pages for clients. It could be that you run a survey software and those web-based surveys, naturally, go live. Meaning that they could be getting indexed, too, resulting in a massive clog in your site's index. A clog that contributes nothing to your SEO, after all.
Again, with the Robots.txt file, you can instruct Google not to crawl URLs in that folder or section of the site.
However, in any other situation, it's perfectly fine to leave the Robots.txt file blank.
This isn't one of those must-do steps in technical SEO for startups.
But I find a good practice to prevent search engines from indexing tag and category pages on your site.
Why? Because those pages, usually, offer no meaningful content anyway. In most cases, they just list whatever content you've published in a category, etc.
So, there's little to no chance that these pages would ever rank. It's also hard to imagine them adding any value to your audience.
Blocking them means that you'll unclog your index AND free the crawler to spend more time on the content that matters.
Most Wordpress SEO plugins like Yoast or RankMath, etc. have that option built in.
Here's what it looks like in Yoast, for example.

If you're not using any SEO plugins in your CMS, then you'll have to use the Robots.txt file for that.
To do so, you need to add code like this to the file:
User-agent: * Disallow: /name-of-the-category/So, if you want to block a category named Tools, and the category URL is /tools/, then the code would look like this:
User-agent: * Disallow: /tools/So far, the actions we took to optimize your startup site for SEO has been pretty straightforward.
Unfortunately, from now on, things get a little more complicated.
For one, you'll have to make some decisions about the site, and possibly also adjust or edit it to ensure it's geared up to compete for traffic and clicks.
And the first thing to do is to optimize the site taxonomy.
We've already talked about website taxonomy earlier in the guide. But let me give you a quick recap.
When we speak of taxonomy we simply mean a classification of something, like information, for example.
And so, site taxonomy is the structure by which you organize content and pages on the site. It ensures that your content is organized in logical way, and as a result, much easier for users to find.
There are many approaches to website taxonomy - hierarhical, feceted, network...
But the thing is, you don't have to worry about a specific approach too much.
After all, your site is small.
What's more, because you sell software, it might never need to become much bigger.
Yet it still needs to present all the information in a logical way, so that users can easily find whatever they're looking for.
I've highlighted the above in italics because, unfortunately, startups often get this part wrong.
So, to make this easier, here's what I suggest you start with.
By far and away, this isn't the only approach. But it works, and you can easily build on it.
This approach uses two menus. The primary (usually at the top of the page) and footer.

Next, you need to ensure that your URLs are SEO-friendly.
But what does it mean, SEO-friendly?
Well, in simplest terms, it means that your URLs should be simple and easy to understand (and short, ideally.)
They should, also, follow the taxonomy, and even make it obvious.
And they should include words that describe the content on the page (ideally, your target keywords.)
In other words, they should help both search engines and humans understand what a page is about.
Why is this so important, though?
The primary reason is that search engines use the URL slug as one of the signals about the topic of the page.
(Which also means that a non-SEO-friendly URL might simply confuse the search engine about it.)
Consider this simple example.
Someone sends you a link. They tell you it's a page about creating SEO-friendly URLs. But the actual link (the URL) is this:
domain.com/guides/link-buildingYou'd be confused, right?
Hell, most likely, you'd also think twice about clicking it. And even if you did, you'd approach the page with caution, unsure what it's really going to be about.
The search engine would react the same way. In fact, many SEOs believe that it makes the first impression of the page by the URL slug (and the link anchor text, if it's not the URL.)
Keep your URLs short. You don't need to include all the folders and directories in the URL.
First of all, long URLs are confusing. But also, they might contain far too much information for the search engine to clearly understand the topic of the page from them.
Compare those two URLs to see it:
TIP: It's fine to use a directory like /features/ but try not to overdo it. One directory in the URL is perfectly enough.
Include the keyword or its closest variation.
I know, I know, this sounds like one of those doh! comments.
But you'd be surprised how often I see sites not following that simple principle.
Instead, they stuff the URL with the entire title of the post. Like this:
domain.com/blog/what-are-the-best-tools-for-managing-user-experience-on-a-startup-siteNow, let me make it clear, there is nothing inherently wrong with that.
But the URL is long, and might be confusing.
This one works much better (and it contains just the target keyword):
domain.com/blog/startup-user-experience-toolsUse hyphens in between words.
It's rare that your URL slug would contain a single word. I even wouldn't recommend it, not for the SEO-driven content anyway.
It's fine for sections of the site like Blog or Shop, of course. But for SEO content, a single word might not be enough to communicate the topic of a page.
This means that you need to include more than one word. And to tell search engines what are the separate words, place a hyphen "-" between them.
So, instead of this:
use hyphens to separate words:
This will make the URL so much easier for the search engines (and users) to read and understand.
Next step - Do what search engines will, too:
Crawl and audit your site.
This first crawl isn't as much about a site audit, though. What you want to do is check how search engines are going to see your newly optimized site, its architecture, etc.
It's also going to show you if there are any outstanding issues (like URLs in the old format, for example, or orphaned pages) that got carried over from before this work we're doing.
Overall, the crawl will tell you about:
You have two main options here:
The first one is to use a dedicated website crawler.
These tools have been built to crawl and evaluate your website against a large number of potential SEO-related issues.
Their main job is to crawl each page, and check how well (or not) it's been optimized.
There is a whole range of crawlers on the market. The two I recommend are:
Or you can use the site audit feature in your SEO platform.
Most such platforms, like SEMrush or Ahrefs, include a site audit capability. It works just like the crawler - it crawls your site and evaluates the technical optimization.
The data these tools deliver is usually sound. However, I found that, overall, these tools tend to cover fewer issues.
Still, it's perfectly fine to use them on a small startup site.
This final item isn't necessarily a step per se. It's more of a habit that I recommend you form early on.
That habit is to check your site's crawlability regularly in Google Search Console.
You should monitor your crawlability not only to identify potential errors that prevent the search engine to crawl your pages. This is important, of course.
But there is another reason...
You see, sometimes, Google decides NOT to crawl or index a particular page. And unless you know about it, you can't take any action to fix it.
There are actually two separate scenarios for this issue:
1/ The search engine learns about the page but decides not to crawl it.
You can tell which pages are affected by this by the "Discovered - Currently not indexed" error in the Google Search Console's Pages report.

This is, by far, the lesser issue of the two. In most cases, what happens is that the search engine actually wants to crawl and index the page, but decides to put it off. It's as if it were too busy to do it now, so it adds it to a list to do later. And, usually, that's exactly what happens. After a while, the search engine finally gets to crawling your page, and indexes it.
So, with this one, I'd recommend that you wait and let the search engine crawl the page naturally.
The other issue is more problematic.
2/ The search engine has crawled your page and decided it's not worthy of indexing.
Such pages are marked with the "Crawled - Currently not indexed" status, and this one is actually quite big.

This issue suggests that something may be wrong with the page:
Unfortunately, Google rarely provides any indication of what the issue is so you need to do a little bit of investigative work to figure it out.
There might be hundreds of such issues but, from experience, they usually center around things like this:
Review your page and be honest with yourself. Is this content really worth being in the index? Is it really original? Does it provide any meaningful information to users?
Remember, Google's (and other search engines') goal is to provide the most valuable information to users. So, they won't index anything that does not help them deliver on that objective.
That's all you need to know to ensure that your startup site is optimized for technical SEO.
As I told you already, you don't have to worry about many other technical SEO elements as they don't pertain to a startup site.
All you need to do is what I've covered above. And unless you deliberately omit something (or break it later,) your site should remain optimized from the technical SEO perspective.
Hey there...
My name is Pawel Grabowski. I am a startup SEO consultant specializing in helping early-stage startups develop and deploy successful SEO programs.
Learn more about me or hire me to run SEO for your startup.